DistiLLM 02
Life has a funny way of keeping us on our toes, doesn’t it? These past few months have been, a whirlwind of errands filling my todo lists. Despite the chaos, I did manage to carve out a bit of downtime to put together this blog post. But let’s face it, they won’t ever be my longterm commitment. Honestly, my goal is not (maybe was) to keep a rundown of what’s happening in or around the industry. Rather, I want this space to be more like a reflection of my thoughts and encounters.
Expect shorter, bite-sized tidbits I stumble upon in my day-to-day life. After all, I don’t wanna carry more burden with me :)
What happened in March 2024?
- March 4th.
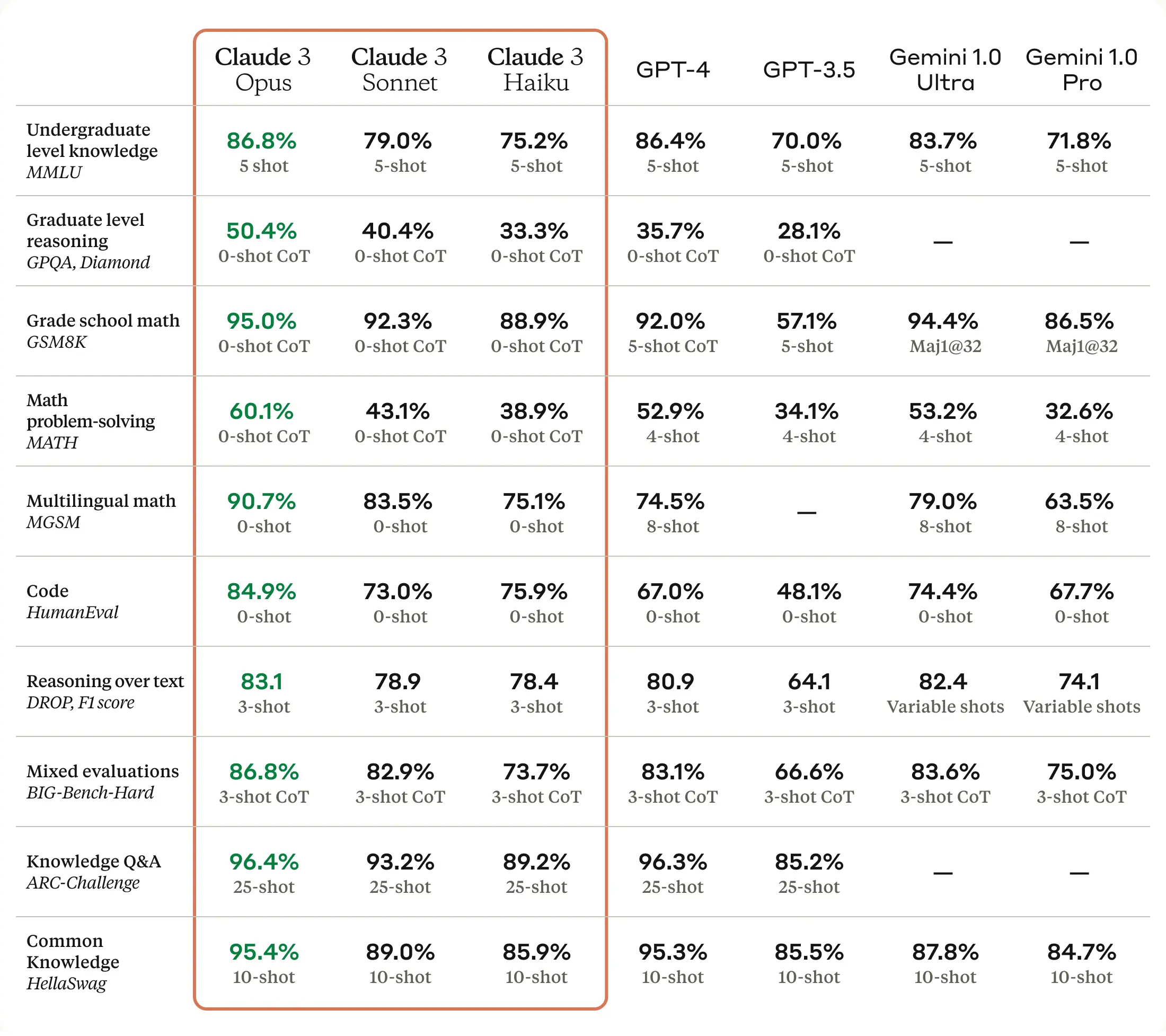
- Claude 3 model family. For some reason, they decide to call them Opus, Sonnet, and Haiku. Opus seems to outperform GPT-4 in many benchmarks.. Context window size bumps to 200k.
- March 5th.
- You can now train a 70b language model at home, a quite detailed walkthrough how the current LLM training procedure is developed.
- HN discussion
- A normal desktop computer setup, combining FSDP and QLoRA, can train a 70b language model.
- QLoRA combines two advanced techniques in modern neural networks: quantization and LoRA.
- 4 or even fewer bits.
- Once quantized, cannot be trained any further using regular approaches–the gradient descent method used will observe zero gradients almost everywhere.
- Quantized models are good for inference but no good for training in this sense.
- LoRA (“Low-Rank Adaptation of Large Language Models”) doesn’t train the whole large language model at all, but instead adds “adaptors”. Use a quantized base model, which is not changed at all by the training, and add trainable LoRA adaptors that are not quantized.
- Batching appears as we need to save time to train multiple sequences together. The batch size available depends on the memory space left after loading the model weights.
- FSDP (Fully Sharded Data Parallel)
- One potential solution to the issue above (not enough memory) is to use more GPUs, e.g., by placing a few layers of the model on each card. When training, run the first few layers on the 1st GPU, then the next few on the 2nd, …
transformershas thisdevice_map='auto'setting does exactly what was described. Downside: only one GPU is active at a time, all the others wait for their “turn”. Note this as IDEA A. - Distributed Data Parallel is the good old standard approach to train models across multiple GPUs by copying the full model on each GPU – to multiple the training speed. But DDP doesn’t work when a full model cannot fully fit on a single GPU. Note this as IDEA B.
- FSDP = `device_map=‘auto’ + DDP
- FSDP is a library, that ‘shards’ a large model, by splitting its parameters across multiple GPUs, allowing all the GPUs to be used simultaneously. When a layer of the neural network is calculated on a particular GPU during training, all the required shards are copied there. Then, the calculation is made, and finally the copied parts are deleted from that GPU. It’s quite efficient to copy the data of the next layer at the same time the current layer is busy calculating.
- One potential solution to the issue above (not enough memory) is to use more GPUs, e.g., by placing a few layers of the model on each card. When training, run the first few layers on the 1st GPU, then the next few on the 2nd, …
- In a later post, Answer.AI - Enabling 70B Finetuning on Consumer GPUs, the team demonstrated how to add FSDP and QLoRA support to quantization libraries and training frameworks.
- You can now train a 70b language model at home, a quite detailed walkthrough how the current LLM training procedure is developed.
- March 6th.
- Paper. [2403.03507] GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection
- Training great LLMs entirely from ground up in the wilderness as a startup
- Not all hardware is created equal. The variance of cluster quality across hardware providers is so high … (even for the same hardware).
- March 8th.
- Paper. Is Cosine-Similarity of Embeddings Really About Similarity?
- Claude 3 beats GPT-4 on Aider’s code editing benchmark | aider
- Claude 3 Opus and Sonnet are both slower and more expensive than OpenAI’s models.
- Claude 3 has 2X larger context window than the latest GPT-4 Turbo.
- March 11th.
- OpenAI’s transformer debugger, a tool supporting investigations into specific behaviors of small language models.
- Paper. Stealing Part of a Production Language Model
- March 13th.
- Figure Status Update - OpenAI Speech-to-Speech Reasoning - YouTube Figure demonstrated a humanoid robot that learns tasks.
- March 14th.
- What I learned from looking at 900 most popular open source AI tools
- Cognition Labs' blog
- YouTube video by Two Minute Paper: The First AI Software Engineer is Here!
- March 20th.
- March 22nd.
- March 27th.
- An article revisited on Mamba Explained | Hacker News.
- Mamba Explained
- March 31st.
- A Builder’s Guide to Evals for LLM-based Applications
- Classification/Extraction: ROC, PR, class distributions
- Summarization: Consistency via NLI, relevance via reward model, length checks
- 4 key dimensions of evaluating abstractive summaries:
- Fluency: Are sentences in the summary well-formed and easy to read? We want to avoid grammatical errors, random capitalization, etc. (not a problem in modern LLM)
- Coherence: Does the summary as a whole make sense? It should be well-structured and logically organized, and not just a jumble of information. (lesser concern in modern LLM)
- Consistency: Does the summary accurately reflect the content of the source document? We want to ensure there’s no new or contradictory information added.
- Relevance: Does the summary focus on the most important aspects of the source document? It should include key points and exclude less relevant details.
- We can reframe the latter two as binary classification and reuse the metrics from classification above.
- To measure factual consistency, we can finetune a natural language inference (NLI1) model as a learned metric.
- Treat the source document as the premise and the generated summary as the hypothesis. If the summary contradicts the source, the summary is factually inconsistent aka a hallucination.
- For relevance, we can develop a learned metric with the same paradigm, or train a reward model on human preferences.
- Opinion summarization: to generate a summary that captures the key aspects and associated sentiments from a set of opinions, such as customer feedback, social media, or product reviews. We adapt the metrics of consistency and relevancy for:
- Sentiment consistency: For each key aspect, does the summary accurately reflect the overall sentiment expressed?
- Aspect relevance: Does the summary cover the main topics discussed?
- 4 key dimensions of evaluating abstractive summaries:
- Translation: Quality measure via chrF, BLEURT, COMET, COMETKiwi
- Copyright: Exact regurgitation, near-extract reproduction
- Toxicity: Proportion of toxic generations on regular and toxic prompts
- A Builder’s Guide to Evals for LLM-based Applications
{kind=link}
Some other stuffs
- How to Match LLM Patterns to Problems
- The Illustrated Transformer by Jay Alammar.
- Eloquent JavaScript (4th ed)
- vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention | vLLM Blog, GitHub - vllm-project/vllm: A high-throughput and memory-efficient inference and serving engine for LLMs
- Discussion about Speech and Language Processing (3rd ed. draft)
- The Tokenizer Playground, a transfromers.js powered web app.
- Hugging Face - Quanto: a pytorch quantization toolkit
- GitHub - OpenGenerativeAI/llm-colosseum: Benchmark LLMs by fighting in Street Fighter 3! The new way to evaluate the quality of an LLM
-
Given a premise and a hypothesis, the task is to predict whether the hypothesis is entailed by (logically flows from), neutral to, or contradicts the premise. ↩︎